Uto-Aztecan Language Research
For further reading - Accompanying Shelf Life article The Language Detectives
In another collaboration with AMNH colleague, Dr. Ward Wheeler (Curator, Invertebrate Zoology), Dr. Whiteley has been studying historical relationships among languages, beginning with Uto-Aztecan languages of Middle and North America, using genetic methods developed in the field of evolutionary biology.
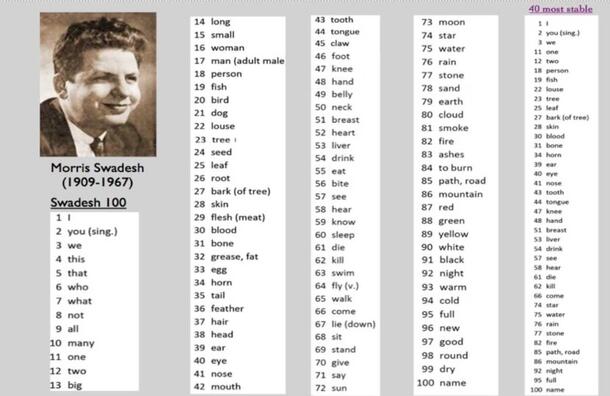
In 1971, a linguist named Morris Swadesh published a list of words most resistant to cross-cultural change. The list, now referred to as the Swadesh list (there are two primary versions, of 100 and 200 words), has been used to reconstruct genealogical relationships among the languages in a language family.
With the phylogenetic software POY, Whiteley and Wheeler systematically compare cognate words as sequences of sounds (phonemes). Where available, they also analyze grammatical (morphological and syntactic) data.
Their paper
appeared in Cladistics (Early View 5-13-2014).
Supplementary Information:
|
Note: PDF/Excel files are made available on condition that downloads will be strictly reserved to private research use.