Machine Learning for Conservation
Machine learning has gone from a relatively niche field of academic research in the 80s and 90s to powering every day services, self-driving cars, and data analyses. Since 2012, the explosion of machine learning has largely been facilitated by advances in the graphic processing units (GPUs) and the availability of massive labeled datasets.
The Center for Biodiversity and Conservation is committed to advancing and promoting the use of machine learning for the understanding and conservation of biodiversity by:
- Cultivating a network of conservation practitioners and machine learning experts to advance the use of machine learning for the understanding and conservation of biodiversity.
- Developing open-source tools and workflows to facilitate the use of state of the art methods and machine learning libraries for the understanding and conservation of biodiversity.
- Developing guides, tutorials, and workshops to introduce and demonstrate, to conservation practitioners, the utility and power of machine learning for the understanding and conservation of biodiversity.
Species Identification and Localization in Camera Trap Images
Bounding Box Editor and Exporter (BBoxEE)
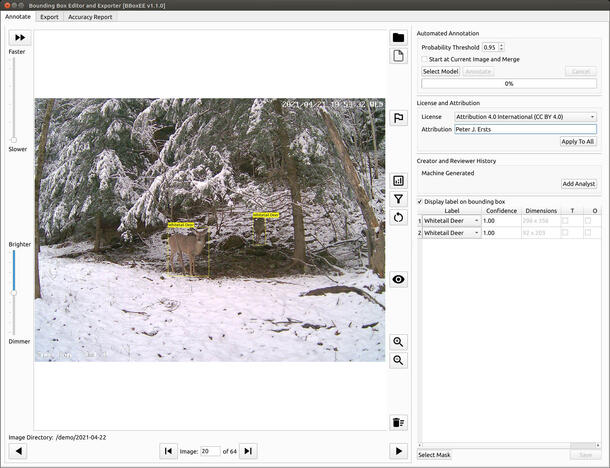
BBoxEE is an open-source tool for annotating bounding boxes and exporting data for training object detectors. BBoxEE was specifically developed for use with camera trap data but it is not limited to annotating camera trap data and can be used for any bounding box annotation task.
A feature that sets BBoxEE appart is the ability to load an existing model and automate the generation of new bounding boxes.
- Several use cases have been created to illustrate potential implementations of BBoxEE.
- GitHub URL
- User Guide
Image Level Label to Bounding Box (IL2BB) Pipeline
Deep learning based object detectors have the potential to assist and automate the analysis of images collected during camera trap deployments. Considerable bounding box data are need to train an object detector. Most organizations, however, don’t have the human capital to manually generate the needed training data let alone reprocess historical or previously labeled images.
The IL2BB pipeline automates the generation of labeled bounding boxes by leveraging an organization’s previous labeling efforts and Microsoft AI for Earth’s MegaDetector. The output of this pipeline are batches of images with annotation files that can be opened, reviewed, and modified with BBBoxEE to prepare data for training object detectors.
Machine Learning for Landcover Classification
In recent years there has been a remarkable trend in the miniaturization and reduction in the cost of electronic components as well as developments in the sensor technologies required to safely control UAVs. Furthermore, the technology is increasingly accessible to organizations and individuals with tight budgets. Improvements in central processing unit (CPU) and graphics processing unit (GPU) technology, paired with recent developments in image analysis and feature recognition through deep learning methods, is increasing the accuracy and efficiency of identifying objects, differentiating textures, and classifying the content of digital images.
The greatest innovation in our proposed work is the leveraging of new machine-learning algorithms for feature recognition and classification. Merging these new and advanced hardware and software technologies provides an opportunity to develop a modular workflow that will enhance data collection to support Earth science studies over large areas.
We are currently developing a modular, advanced data analysis pipeline that classifies high resolution aerial images into land cover classes. Our open source tool will facilitate collecting training data, training deep learning models, and classifying high resolution aerial images. The tools will be flexible and allow the same training data to be used to train a wide variety of deep maching learning models(e.g., neural networks and convolutional neural networks.)
Neural Network Image Classifier (Nenetic)

The Neural Network Image Classifier (Nenetic) is an open source tool written in Python to label image pixels with discrete classes to create products such as land cover maps. The user interface is designed to facilitate a workflow that involves selecting training data locations, extracting training data using original image pixel data and computed features, building models, and classifying images. The current version works with 3-band images such as those acquired from typical digital cameras.
Nenetic was designed for testing different neural network designs and experimenting with model parameters. It is an excellent teaching tool to learn how different neural network designs can be used to classify remotely sensed images, especially those with ultra-high spatial resolution.
To classify an image, Nenetic applies neural network algorithms to vectors or image chips created from user selected regions around a central pixel. Training data are collected using points that can be selected one at a time or as a stream. Extracting training data for each point is accomplished using a dialog that allows a user to select features that will be used for training and classification. Available feature selection options include; calculating average pixel values for multiple region sizes, selecting all pixels in a neighborhood around a training point, and calculating a series of RGB indices, such as NDVI and luminosity, for all pixels in a neighborhood with dimensions defined by the user.


